AI 4 GOOD was organised on the 28–31 May 2019, in Geneva, Switzerland by ITU (itu.int) in partnership with sister UN agencies, the X-Prize Foundation (xprize.org), and the Association for Computing Machinery (acm.org). The “AI for Space” session hosted inspiring talks from top industry professionals, focusing on areas where AI techniques can be applied to space datasets in order to accelerate progress towards the Sustainable Development Goals (SDGs). It also covered the processes, infrastructure and ethical considerations when using this powerful technology to protect our planet and generate benefit for all humankind. The session was joined by Pierre-Philippe Mathieu, Head of Φ-lab Explore office, who presented cutting edge use-cases, methodologies and emerging best practices to delegates, including the fusion of ESA data sets to create enhanced products and ways of working with partners to build consortia to tackle complex challenges such, as the SGDs, using space technology.
Participants at AI 4 Good Global Summit. Credits. AI 4 Good.
The discussion placed emphasis on the potential for AI and space to unlock a new era of planetary stewardship – leveraging AI’s unprecedented capacities for prediction and rapid understanding of complexity on both a local and global scale. The session involved evaluations on the current state of play in AI and Space, barriers to deployment and real-time insight and equitable access to data. It identified projects related to SDGs where AI and Space fields can be combined to deliver a positive benefit to humanity and discussed opportunities for interdisciplinary cooperation to move forward in areas such as data accessibility, trust, algorithmic inequity, and accountability.
The Rise of AI event is one of the leading global conference for AI. In Berlin, 2019 Rise of AI hosted over 800 investors, CEOs, researchers, politicians, entrepreneurs and enterprises.
ESA participated with the AI demo: how to apply AI on Earth data. This demo, supported by the Φ-lab, focused on how to get insights out of satellite imagery with AI. The demo allowed selected AI start-ups seeking to exploit the opportunities brought by this disruptive domain, to present themselves through a set of talks.
LiveEO mastered the challenge of handling big data and showed how it is disrupting the utility sector. LiveEO uses satellite imagery to provide innovative infrastructure monitoring in the verticals railway, electricity and pipelines networks. It provides a solution which uses satellite data to identify risks to operations from vegetation, height changes and third party interaction along networks, enabling operators to work more efficiently.
Another startup, Bird.ai showed how they are giving customers insight into the degradation of their assets so they can proactively perform maintenance in order to keep them in top-condition. Their toolset contains artificial intelligence, machine learning, and predictive analytics. With this, Birds.ai creates intelligent analytical software for anomaly checks, functional statistics, and intelligent monitoring.
Start-up pitching at the Rise of AI (top) LiveEO, (bottom) Bird.ai. Credits: Rise of AI
Quantum Processing of Big Data: from Quantum Computing to Earth Observation
On 3 April 2019 a workshop was held at La Sapienza University in Rome, on the application of Quantum Computing for Earth Observation (with a focus on downstream data exploitation). The workshop had the following aims:
Introduce the Quantum Computing and Earth Observation communities (from both research and industry)
Explore possible synergies between the two technologies
Prepare the ground for the opportunities that will be presented when the quantum community will be able to produce software for quantum-enhanced optimisation problems of direct use in big data management.
The workshop was jointly organised by ESA, the COST Action QTSPace (CA15220) and La Sapienza University of Rome. It was held on the occasion of the Fifth Quantum Technologies Conference.
This is a short MOOC from ESA which consists of a series of interviews with leading experts across Earth Observation and related technologies. This MOOC also acts as an additional section for the ‘Earth Observation from Space: The Optical View’ MOOC.
The explosion in Earth Observation (EO) data from the Sentinel programme, a new generation of commercial satellites, and emerging constellations of small-sats, has created one of the greatest ‘big data’ challenges in the world today. In this course you will explore technologies such as AI, 3D data visualisation, cloud computing technologies and blockchain, and learn how they are meeting the needs of the ever growing data analytics and data navigation challenges in EO.
Enroll now in the course, clicking on the image below.
The Pi School is a next-generation school focused on building a better future through technology and creativity. The Φ-lab brought two EO challenges to Pi school to be developed over the course of eight weeks. The projects exploited free and open data from Europe’s Copernicus satellites, whose data is useful for a range of applications in various domains, from climate change to urban planning. Both projects demonstrated new aspects of the use of AI in terms of climate change and sustainability.
The first challenge addressed the agriculture sector and aimed at developing a proof of concept that will help monitor the crop fields all over Europe. The proof of concept, “SmartCrop”, was the result of work carried out during the eight-week programme. It aims at distinguishing different types of field crops contains (soybean, wheat, corn, etc.) using satellite images and deep learning techniques. Crop classification served as a starting point for several use cases related to improving the current state of the art in the field of agriculture by using AI. Adding space-based observation data to traditional crop-forecasting models enables more accurate harvest predictions and helps farmers to monitor the health of their crops and plan deployment of fertilisers.
Another challenge, also sponsored by Φ-lab was to explore the available solutions that will enable countries to to monitor emissions and improve adaptation and mitigation efforts – through air pollution forecasting. This eight-week challenge aimed at predicting levels of air pollution and air quality, through mathematical simulations of how pollutants dispersed in the air. This downscaling air quality forecast used Copernicus Atmosphere Monitoring Service (CAMS), and Sentinel-5P, to create a weather-forecasting model developed with deep-learning techniques.
Jamila Mifdal and Teodora Selea at Φ-lab developing the eight-week challenge and presenting the proof of concept that will help monitor the crop fields all over Europe. Credits: PI School.Luka Sachsse and Maximilien Houël teamed up for eight-weeks at Φ-lab and presented the enhancement of weather-forecasting model working at based on EO data and deep-learning techniques. Credits: PI School.
The Quantum Computing for EO workshop will take place in April 3 in La Sapienza University in Rome.
At this event representatives from the Quantum Computing community, from both academia and industry, met with Earth Observation practitioners.The aim was to explore possible synergies between the two technologies to stimulate their further development and to accelerate their impact for societal benefit.
Read the event page to find more information about the workshop.
Machine Learning glossary: some false friends in Earth Observation and Computer Vision
Quick introduction
If you are an expert in Earth Observation (EO) and you would like to apply the latest methodologies of Machine Learning like Deep Convolutional Neural Network to carry-out EO analysis in a data driven approach, or if you are an expert in Artificial Intelligence and you would like to apply your knowledge in Computer Vision in a Remote Sensing domain, you might want to make sure that you have the correct meaning of some words in mind when you migrate from one domain to another.
Beware of false friends
#1 CLASSIFICATION
One of the first differences in wording I have noticed is related to the word classification: in Computer Vision the word classification includes the type of Supervised Learning problems which has classes (e.g. good, bad) as output type. This includes different types of sub-categories:
Image Classification: the model predicts if a certain class (e.g. cat, dog etc) is present in the picture
Object Detection: the model predicts if a certain class (e.g. cat, dog etc) is present in the picture and where it is located (e.g. Bounding box and location)
Image Segmentation: the model predicts for each pixel in the image the class that it belongs to
Figure1 Top left: example of Input image; top right: output of a classification; bottom left: output of an Object detection; Bottom right: output of image segmentation.
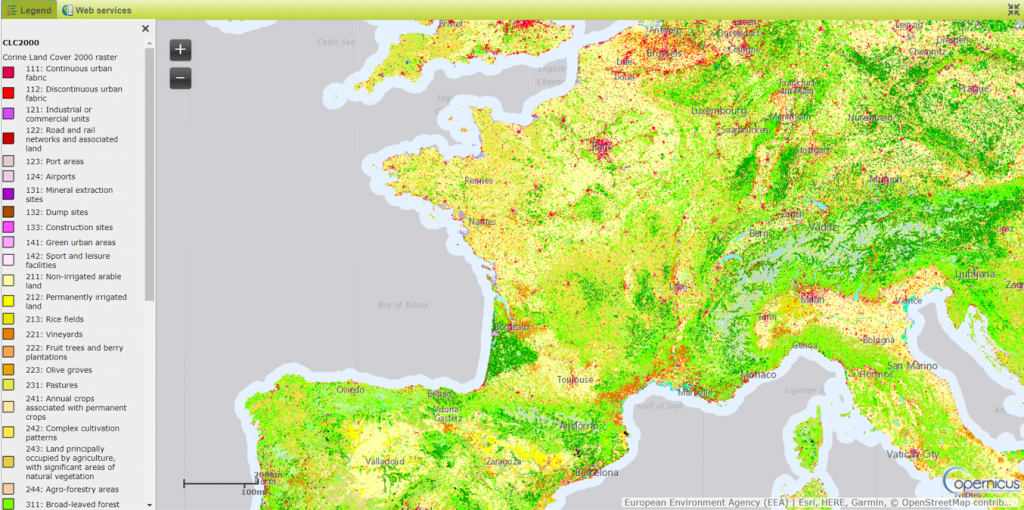
In Earth Observation the term classification includes a set of different products like Land cover or Land Use. An example of this is the Corine Land cover in Figure 2.
Figure 2: Example of Land cover classification
As you can see those types of EO products are the equivalent of an image segmentation in the computer vision domain but the wording in EO comes from the objective of map which is actually to classify –in this case- the different type of Land Cover.
#2 VALIDATION DATASET
Another element of misalignment which I have noticed sometimes between EO experts and Computer Vision experts is related to the usage of the term validation datasets.
In Computer Vision or more generically in Computer Science, the standard approach in Supervised Machine Learning is to split the dataset in Training, Validation and Test sets. Where:
Training Dataset: The sample of data used to fit the model.
Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters. The evaluation becomes more biased as skill on the validation dataset is incorporated into the model configuration.
Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
On top of this, once the model is transferred to a production/operational chain, it is important to evaluate its performance also there.
In my experience, the meaning that the Earth Observation domain associates to the term “validation” is inherited more from the software engineering field where the validation process aims to verify that the system is doing the “right thing” and not just the “things right”.
The validation process includes also the data collection and data evaluation, from the process design stage and throughout production, which establishes scientific evidence that a process is capable of consistently delivering quality products. That’s why also in the Earth Observation domain you can hear about validation campaigns which aim to verify that a sensor in space is working as expected and it is generating data consistent with the model.
So you can imagine what kind of misunderstandings can be generated in a discussion where an EO expert is asking a Machine Learning expert: “do you have a validation dataset?”.
#3 TRAINING DATA SET
Last but not least, I have noticed in several conversations an improper usage of the wording “training dataset” in the EO domain. Sometimes EO experts refer to ground truth data, information collected on the Earth in a certain location (e.g. a national forestry inventory), as training dataset, while in the Machine Learning domain, training dataset is intended to mean the joint input / expected output, one to one association. This has on several occasions created a non-trivial misunderstanding/ambiguity because one thing is to start a Machine Learning project with/while in possession of a training dataset, and another is to start a project where you have to build it.
I would also like to raise awareness –to the AI experts- of the high probability of misalignment between ground truth data and remote acquisitions which should not be underestimated when planning to build a dataset. To give you the simplest example, imagine that you have a map (a ground truth map) of an area after a fire and that you want to use this to build a training dataset with EO data. Your aim will be to train a model which will then be able to automate (in computer vision I would have to say “predict” but this might be misleading for an EO expert here J ) the mapping of burned areas but, e.g. if you use an optical sensor, you might have cloud in that area.
This, the association of data to value (input/ expected output), required an enormous effort in the generation of the ImageNet dataset which was one of the enablers of the AI revolution we are witnessing in these years. On the other side the objective of remote sensing goes beyond simple image classification or segmentation or object detection (think about snow-water equivalent or biomass estimation) which require a level of expertise that cannot be delegated to the crowd -as we generally say, It’s not a cat/dog problem-. Because of this, I personally believe that the EO domain offers to the AI community great challenges and I am looking forward to seeing how this cooperation will grow in the future.
Conclusion
I only have one recommendation in this particular case which is applicable to any communication context but much more when different domains meet each other: “Do not take anything for granted!”, ask , make sure there is a common understanding and share your knowledge!
Last week, ESA’s Φ-lab welcomed partners from the World Wildlife Fund (WWF) and the Food and Agriculture Organization of the United Nations (UN-FAO) for a collaborative workshop elaborating the potential use of Sentinel-1 SAR data for some of their projects. Both organisations traditionally work a lot over tropical regions where cloud coverage hinders the regular mapping of the environment with optical datasets.
It is well known that SAR sensors, thanks to their active SAR antennas, can acquire data independent of cloud cover and daytime. On the other hand, the underlying physical principles are fundamentally different to optical sensors such as Sentinel-2 or Landsat. This confronts new users with difficulties regarding proper image processing and interpretation, as well as an adequate use of the data for various tasks related to environmental monitoring.
The workshop was therefore targeted to de-mystify SAR data by giving practical examples of Sentinel-1 processing workflows and adapt them to specific problem statements such as the mapping of de-forestation and mangrove forests, the identification of water holes as well as the large-scale mapping of crop types.
RGB Sentinel-1 Timescan composite over the northeast of Borneo island in Malaysia. The green area in the center is the Tabin Wildlife ResortWWF, ESA and FAO participants
A special focus was put on the innovative use of the free and openly available data of Sentinel-1, whose radar eyes cover the entire earth with a minimum of 12 days repeat, and produce around 10 TB of raw data every day. While the availability of this amount of data allows for completely new ways of extracting ever more detailed information on large scales, it also confronts the users with issues regarding the data handling and information extraction. Both partner organisations are mainly using Google’s online platform Earth Engine to tackle this issue, and respective processing strategies have been presented there. In addition, the SNAP based Open SAR Toolkit has been introduced, which allows for an almost fully automatic production of large-scale, analysis-ready SAR imagery and provide a more customisable way of processing for non-SAR experts. Its incorporation of Jupyter Notebooks allows for an eased usage on remote machines in cloud environments such as the Copernicus Data Information and Access services (DIASes) or FAO’s Sepal platform.
Finally, techniques of how to ingest the analysis-ready SAR data into machine-learning and AI frameworks have been discussed. While those techniques have been around for a while, they gain more and more importance with the constantly growing amount of satellite data. On this part, future collaborations between phi-lab and both organisations are foreseen in order to support an effective use of Copernicus data to help WWF and FAO in achieving important goals such as wildlife conservation and a world without hunger.
The FDL (Frontier Development Lab) Europe presented the work done at the Neural Information Processing Systems (NeurIPS) annual conference. The purpose of the conference is to foster the exchange of research on neural information processing systems in their biological, technological, mathematical and theoretical aspects. The core focus is peer-reviewed novel research which is presented and discussed in the general session, along with invited talks by leaders in their field. FDL Researcher Valentina Zantedeschi presented Cumulo, a breakthrough dataset and method of fusing radar and image data for improved cloud classification. This was also awarded the best paper in the Climate Change research workshop, which is a fantastic achievement. Josh Veitch-Michaelis, FDL Researcher for the Disaster Response team, presented the Flood Detection on low cost orbital Software at the AI & HADR (Artificial Intelligence for Humanitarian Assistance and Disaster Response) Workshop. The mission support challenge team were also accepted to present their work at the Machine Learning competitions for all workshops.
The FDL (Frontier Development Lab) Europe participants presenting the work done at the NeurIPS annual conference. Credits: FDL Europe.
An international conference and workshop on 7-8 November 2019 in Rome, Italy, organised by the European Space Agency (ESA) and the British School at Rome (BSR).
Artificial Intelligence, Machine Learning and Deep Learning are opening new frontiers of inquiry. Join the BSR and ESA in exploring applications of Machine Learning in artifact analysis, text mining and remote sensing. Papers will be presented at the BSR on November 7, followed by a workshop at ESA’s European Space Research Institute (ESA/ESRIN) on November 8








![[ESA MOOC] Earth Observation – Disruptive technology and new space](https://philab.esa.int/wp-content/uploads/sites/3/2021/05/delete2-1-1.png)