

Physical domain knowledge of dynamic systems is normally encoded in the form of numerical models. Various applications make use of such models, for instance in acquiring better operational weather and ocean forecasts. There are various data assimilation techniques previously designed to take observational data acquired from noisy sensors and combine it with outputs of numerical models, to produce an optimal estimate of the evolving state of the system.
Data assimilation techniques have several strengths in combining independent variables such as handling missing data and the implicit treatment of noise. However, the use of available data assimilation algorithms is difficult, mainly because there are many choices to be made by their user. Given a physical model and a set of observational data, there are many data assimilation algorithms to choose from. Each of these algorithms has a different set of hyperparameters that need to be tuned.
Additionally, models need to be parameterised before being used in combination with an algorithm. Identifying the optimal set of parameters and algorithms is purely a matter of trial and error and the choice depends on the dataset at hand. Therefore, users of these methods can benefit from a system that can identify the set of optimal choices in a computationally efficient way. This research focuses on automating the process of selection of the most suitable algorithm and set of parameters for each dataset.
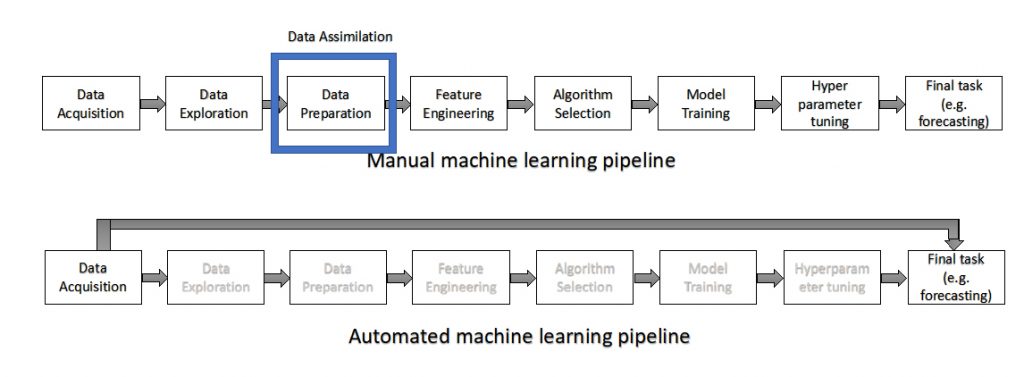
This work fits within the context of a wider area of automated machine learning from spatio-temporal Earth observation data. Before using data as an input to many machine learning algorithms, many steps are performed. All these steps require difficult decisions to be made by a domain expert. Automating the process of making such decisions allows for easier use of these techniques and simplifies acquiring machine learning models from data. Automated machine learning aims to find computational solutions for automating those tasks in the machine learning pipeline that purely depend on trial and error. Data assimilation can be considered as one of the techniques that can be performed as part of data preparation (e.g. by creating a de-noised time series from raw observations). An automatic solution for data assimilation allows for easier use of these techniques while designing machine learning pipelines, and thus better use of available domain knowledge encoded in physical models.
Recent advancements in the area of algorithm selection and hyperparameter optimisation have been employed to jointly select from the available algorithms and also to parameterise them. Our evaluation results acquired from experiments on a data assimilation benchmark show that for a given dataset, it is possible to choose the best data assimilation algorithm automatically and set the algorithm and model parameters. More importantly, the computational complexity of this task, which is directly related to the number of evaluations needed in each data assimilation round, is relatively low. This fact allows the applicability of automated data techniques within time-critical applications.




