

Hyperspectral Imaging (HSI) has become a mature technology which creates exciting possibilities in various Earth observation applications in a plethora of fields, including precision agriculture, forestry, event detection and racking. This toolbox is aimed at addressing the most important challenges to enable more effective hyperspectral image analysis, together with developing techniques and tools that will help extract value from such highly dimensional image data.
Since the approaches are generic, they can be easily deployed in a range of real-life applications, thereby enabling easier adoption of this revolutionary technology in practice.
Tools include a comprehensive and ready-to-use software suite for hyperspectral image analysis, not only encompassing classification/segmentation algorithms, but also various techniques for data reduction, feature selection and extraction, visualisation, optimisation, batch analysis and processing, and much more. It also ensures that users can seamlessly load data using widely available hyperspectral data formats. The Jupyter notebooks make understanding of the software straightforward and allow a new user to quickly go through the internals of the package.
The algorithms were verified and validated in the wild, and results were presented and published in several scientific journals.

Supervised classification and segmentation of hyperspectral images
Although the number of manually annotated ground-truth hyperspectral sets is still limited, supervised classification techniques are being actively developed in the literature. Here, the deep learning-powered algorithms have established the current state of the art in the field.
State-of-the-art deep networks for hyperspectral image classification have been implemented (a spectral-spatial neural network alongside a convolutional neural network with multiple feature learning), along with the attention-based convolutional neural networks (which allow users to additionally determine the most informative bands during the training process) and various spectral models.

Unsupervised segmentation of hyperspectral images
Although DL has established the state of the art in the field, it remains challenging to train well-generalising models due to the lack of ground-truth data. Tackling this problem led to an end-to-end approach for segmenting hyperspectral images in a fully unsupervised manner.
This introduces a new deep architecture, which couples 3D convolutional autoencoders (3D-CAE) with clustering, showing that it can be used to process any hyperspectral data without available prior class labels.
Transfer learning for hyperspectral image classification
This shows how to effectively deal with a limited number and size of available hyperspectral ground-truth sets and apply transfer learning for building deep feature extractors in the supervised setting. Also, the spectral dimensionality reduction is exploited (by simulating wider spectral bands) to make the technique applicable over hyperspectral data acquired using different sensors, which may capture different numbers of hyperspectral bands.
The experiments, performed over several benchmarks and backed up with statistical tests, indicated that this approach allows effective training of well-generalising deep convolutional neural nets even using significantly reduced quantities of data.

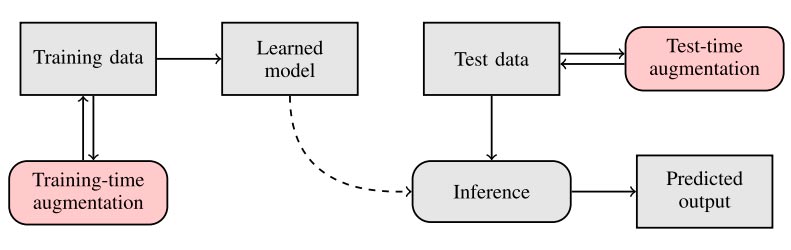
Training-time and test-time augmentation of hyperspectral data
Data augmentation helps improve the generalisation capabilities of deep neural networks when only limited ground-truth training data are available. This tool addresses test-time augmentation of hyperspectral data, which is executed during the inference rather than before the training of deep networks. It also introduces two augmentation techniques, which can be applied at training time and test time and exploitation (e.g., principal component analysis-based approaches).
The experiments revealed that the augmentations boost the generalisation of deep models and work in real time, and the test-time approach can be combined with training-time techniques to enhance the classification accuracy. Finally, the implementations include other state-of-the-art hyperspectral data augmentation algorithms, including generative adversarial networks and noise injection.
Validating hyperspectral image classification and segmentation
Validating hyperspectral image segmentation algorithms is a challenging task due to the limited number of manually annotated ground-truth sets. Practically all segmentation techniques have been tested using up to three benchmarks, with Salinas Valley, Pavia University and Indian Pines constituting the mainstream. A common approach is to extract training and test pixels from the very same hyperspectral scene, and almost all algorithms are being validated in the Monte-Carlo cross-validation setting. Such random selection of training and test sets may, however, lead to overly optimistic results, since a training-test information leak can occur, especially for spectral-spatial algorithms.
To address this issue, a tool was developed for elaborating patch-based training-validation-test splits, which helps quantify the classification performance of emerging hyperspectral classification algorithms without any information leakages.
This tool has been used to elaborate the splits that are publicly available.
Attention-based CNN for hyperspectral band selection
To reduce the time, and ultimately, the cost of transferring hyperspectral data from a satellite back to Earth, various band selection algorithms have been proposed. They are built on the observation that for a vast number of applications, only a subset of all bands conveys the important information about the underlying material, hence the data dimensionality can be safely decreased without deteriorating the performance of hyperspectral classification and segmentation techniques.
Here, a novel algorithm is introduced for hyperspectral band selection that couples new attention-based convolutional neural networks, used to weight the bands according to their importance, with an anomaly detection technique exploited for selecting the most important bands. The proposed attention-based approach is data-driven and reuses convolutional activations at different depths of a deep architecture, identifying the most informative regions of the spectrum. Additionally, other state-of-the-art band selection techniques were implemented, including both filter and wrapper approaches.





